
面试准备(热更)
面试准备(热更)
初入职场必备丨二进制面试问题汇总 - FreeBuf网络安全行业门户pwn方向的分析 预计中旬左右
操作系统
软链接
https://blog.csdn.net/annita2019/article/details/105481449
https://blog.csdn.net/kfepiza/article/details/136095095
ln -s
创建软链接
然后区分一下/usr/bin和/usr/local/bin的区别
/usr/bin下面的都是系统预装的可执行程序,系统升级有可能会被覆盖./usr/local/bin目录是给用户放置自己的可执行程序.,不会被系统升级而覆盖同名文件。
匿名页(TODO)
mount挂载
参考文章:【Linux】Linux的挂载原理 |MOUNT|挂载NAS|自动挂载-CSDN博客
linux的mount结构与原理_linux mount原理-CSDN博客
mkdir 命令加了-p后可以在多级目录的父目录不存在的时候创建目录比如
mkdir -p test/test2 如果test不存在就创建test
我们也可以通过fdisk -l 或者more /proc/partitiions查看系统硬盘分区情况
挂载mount /dev/sda3 /mnt
指的就是将设备文件中的顶级目录连接到Linux根目录下的某一目录,访问此目录就等同于访问设备文件。
值得注意的是挂载操作会使得原有目录中文件被隐藏,所以我们习惯于创建一个新的目录作为挂载点
- /dev/sda3 是挂载的分区 根目录下的
/dev/目录文件负责所有的硬件设备文件,当我们设备接入系统后,会在dev目录下创建一个目录文件比如/dev/sdb1 这个目录提供了一些基本的信息 - /mnt是挂载点
- 出现报错:device is busy 可以用
lsof指令(list open file)查看一下正在被使用的文件 也可以用fuser-m
- /dev/sda3 是挂载的分区 根目录下的
解挂umount /mnt
参数
- -t 指定文件系统的类型
- -o 用于描述设备的挂载方式
- loop 把文件当作硬盘分区挂载上系统
- ro 只读
- rw读写
回环设备(TODO)
参考文章:linux磁盘之回环设备 - jinzi - 博客园 (cnblogs.com)
回环设备( 'loopback device')允许用户以一个普通磁盘文件虚拟成一个块设备。(磁盘文件 --> 块设备)
套接字
套接字是一个重要的概念。套接字是一种用于网络通信的接口,它可以实现进程之间的通信和数据传输。在使用套接字进行网络编程时,关闭套接字是一个必要的操作。关闭套接字可以释放资源,避免程序出现内存泄漏等问题。在关闭套接字时,我们通常会用到 close() 和 shutdown() 函数。这两个函数虽然都能够关闭套接字,但是它们的使用方式和作用有所不同。
当调用 close() 函数时,文件描述符的引用计数减1。只有当引用计数变为0时,文件描述符才真正被关闭,并且与其相关的资源被释放。
- 在fork的时候 子进程会让所有文件描述符copy下来 并且引用计数+1 close本质是对文件描述符的引用计数进行的减1
Linux 中内存管理
这里有总结linux内存管理(详解) - 知乎 (zhihu.com) 根据总结来进行学习
tcp和udp区别
直接看博客中写的文章 这里就不重复赘述了
四种锁的区别(TODO)
cow 与row
这里涉及快照的概念 COW、ROW快照技术原理 - 华为 (huawei.com) 快照就用了cow
写时复制(Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。性能较为低下 因为会导致父节点更新 导致写放大也就是本来期望修改一个节点 但是会导致需要修改4个节点之类
- 简单来说就是 不修改就不拷贝 修改再单独拷贝
用途
- 虚拟内存管理中的写时复制
- 一般共享访问的页面标记为可读 然后当一个task尝试写入数据的时候
内存管理单元(MMU)会抛出一个异常 内核处理该异常 并且为task分配一个物理内存并复制数据到次内存到中 重新向MMU发出执行该task的写操作
- 一般共享访问的页面标记为可读 然后当一个task尝试写入数据的时候
- 数据存储的写时复制(cow)
- linux等文件管理系统采用了cow策略
- 数据库也采用了该策略
- 软件应用的写时复制
- cpp中std::string类 以前采用 后面禁止了
虚拟内存
秋招复习笔记——八股文部分:操作系统 - 知乎 (zhihu.com)
[【操作系统基础】内存管理——虚拟内存概念及分页机制 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/651057404#:~:text=通常一个页表项需要记录20bit的物理页号,因此这样一个虚拟内存管理系统分配给一个程序的页表至少需要2^20*20bit的容量,至少是2.6MByte,而如果是64bit的地址空间,一个页表至少是11%2C258%2C999GByte。 这种机制显然是不合理的。,因此操作系统通过多级页表的方法减少驻留在内存中的页面尺寸,减小页表。 具体来讲,高层页表的页表项并不保存物理页号,而是保存下一级页表的起始地址,如同页表基址寄存器的功能一样。 在这种方式下,操作系统不需要把所有的页表项都存放到内存中,部分页表项成为空洞,在需要用到这个页表项对应的空间时才进行填写。)
操作系统通过多级页表的方法减少驻留在内存中的页面尺寸,减小页表。
- 虚拟空间连续 但是物理空间不一定连续
- 当内存空间不足的时候 会把其他正在运行的进程 最近没有使用的内存页面释放暂时写在硬盘上 然后需要了就加载回来
- 和中断处理机制一样用了选择子和页内偏移的方式来寻址 我们通过页号来获取基础地址再加上页内偏移
- 多级页表
- 通过多级页表来实现逻辑地址到地址的映射
虚拟地址的cow
- 不同的进程是可以让虚拟地址共同映射到同一块物理内存地址的
内存对齐
- 要是不对齐的话 系统需要花费额外的操作去读取 十分浪费性能 自然对齐性能利用率高
- 这里提及的额外的操作是因为比如32位机子 一次性读取数据就是32位也就是4字节 64位操作系统一次性读取是64位也就是8字节
- 假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的联系四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器。这需要做很多工作。
管道
[进程间通信(IPC) 系列 | 管道(pipe) - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/423964093#:~:text=所谓管道,是指用于连接一个读进程和一个写进程,以实现它们之间通信的共享文件,又称 pipe,文件。 向管道(共享文件)提供输入的发送进程(即写进程),以字符流形式将大量的数据送入管道;而接收管道输出的接收进程(即读进程),可从管道中接收数据。)
管道中最重要的2个方法就是管道的读写。从上述的分析来看,读写进程共同操作内核中的数据缓冲区,若有缓冲区可写,则进程往缓冲区中写,若条件不允许写,则进程休眠让出 CPU。读操作同理。
从上述管道读写操作可知,父子进程之所以能够通过 pipe 进行通信,是因为在内核中共同指向了同一个pipe_inode_info 对象,共同操作同一个内存页。
返回的文件描述符是一个数组:fd[0] fd[1] 0表示读取 1表示写入
- pipe文件
- 互斥性 就是管道有一方进行读写操作的时候 另一方必须等待
- 同步性 管道必须写入后/读取后 然后进入睡眠 等待下一步操作
- 检测对方是否存在
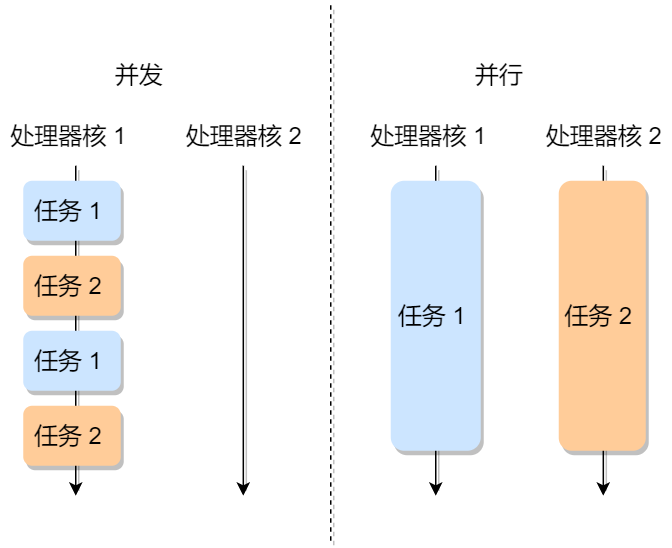
并发与并行
[并发与并行的区别(超级通俗易懂)_并发和并行区别秒懂-CSDN博客](https://blog.csdn.net/scarificed/article/details/114645082#:~:text=并发是指一个处理器同时处理多个任务。 并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。,并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。 来个比喻:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。)
- 并发是一个cpu同时处理多个任务 单一时间只能执行一种指令 但是在各个任务之间来回切换
- 并行是多个cpu同时执行多个任务 多个任务物理意义上的同时运行
文件描述符
件描述符(file descriptor)就是内核为了高效管理这些已经被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符来实现。同时还规定系统刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。这意味着如果此时去打开一个新的文件,它的文件描述符会是3,再打开一个文件文件描述符就是4......[彻底弄懂 Linux 下的文件描述符(fd) - 锦瑟,无端 - 博客园 (cnblogs.com)](https://www.cnblogs.com/cscshi/p/15705033.html#:~:text=文件描述符(file,descriptor)就是内核为了高效管理这些已经被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I%2FO操作的系统调用都通过文件描述符来实现。 同时还规定系统刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。)
- 进程之间文件描述符相互独立 可以互不影响
- 可以通过fork让 不同的进程之间 同一个文件描述符指向 同一个文件
本质也就是先用一个数组来存每个进程的空闲文件描述符数组 然后数组存储的是一个下标再指向真正的文件描述符数组 然后里面存储着详细信息 包含filenode等信息就可以找到文件本体了
fork函数
论fork()函数与Linux中的多线程编程 - 知乎 (zhihu.com),
有关 COW (CopyOnWrite) 的一切 - 知乎 (zhihu.com)
操作系统需要将父进程虚拟内存空间中的大部分内容全部复制到子进程中(主要是数据段、堆、栈;代码段共享)
fork还是接触比较多 在程序中或者ctf题中 有时候fork可以带来一些新的思路
fork函数是创建一个新的进程 并且copy 父进程的栈堆代码等段信息
子进程会获取父进程的所有文件副本 所以文件描述符也是操作的对应一样的文件
当fork函数调用用了新的进程后 如果马上调用exec加载新的程序 那么fork之前执行的栈堆代码段等的拷贝就是白用工 胡总和说性能损失巨大 所以fork函数采用了cow技术 只有当进程尝试写入共享区域的某个页面的时候 才会为这个页面创建一个新的副本
- exec并不会导致pid的改变 直接将新的程序的用户空间代码和数据完全替换当前进程
虚拟内存管理技术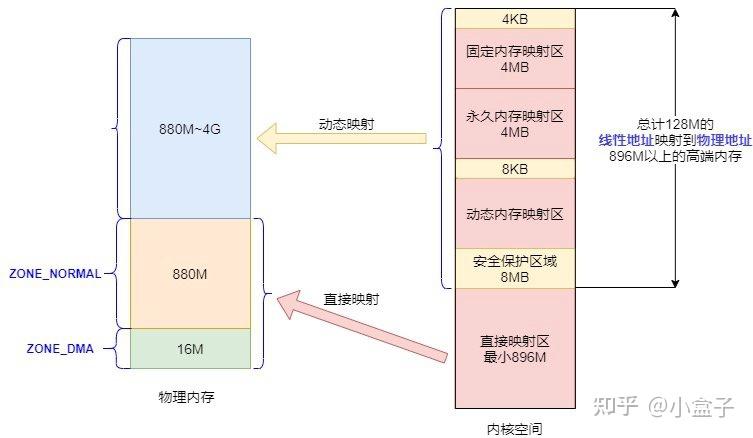
img 只有当进程实际访问内存资源的时候才会建立
虚拟地址和物理地址的映射 调入物理内存页直接映射区
- 前(最小)896mb的内核空间是与物理地址前896mb 直接进行的映射
动态内存映射区
- 该区域由
vmalloc进行分配 线性空间连续 对应的物理空间不一定连续 可能是处于低端或者高端的内存中
- 该区域由
永久内存映射区
- 这个区域可以访问高端内存
alloc_page分配高端内存页 kmap函数可以通过将高端的内存映射到该区域去
- 这个区域可以访问高端内存
固定内存映射区
- 这里的地址有特殊用途
fork的cow技术
当创建子进程的时候父进程直接将
虚拟内存到物理内存的映射关系复制到子进程中 并且将内存设置为只读这样写入的时候就会触发缺页保护当不同进程要对内存数据进行修改的时候就会触发
写时复制(cow)机制 才会进行拷贝
image-20240511234355582 触发
缺页异常后 内核在缺页异常的回调处理函数中进行物理内存页的复制 并且把内存页设置为可读可写状态
重定向
- 1>也就是标准输出流定向到某个文件种
- 2>也就是错误输出流定向到某个文件种
所以在禁用了1情况下可以通过重定向到0
以及其实直接向0输出也是可以的 但是pwntools在本地是无法接受到这个的
信号中断
类型
我们可以大致把中断分为中断和异常 异常还分为故障 陷阱 中止 中断还有:硬中断 软中断之分 硬中断也就是中断异常这类 而软中断比如:int 0x80之类的
- 中断是异步的
- 比如鼠标点击之类的
- 异常是同步的
- 比如cpu的异常事件 缺页异常 错误指令异常等
- 软件中断
- 与硬中断不同 硬中断是每完成一个生命周期后都会去检测一下有没有中断信号 然后去完成中断处理操作 而软中断是单独有个守护进程不断轮询标志位 软中断更类似于注册了一个对象列表 然后不断轮询这个列表查看标志位 如果标志位发生了改变 就去调用对应的处理函数 这是一种比较先进的思想
- 硬中断更像是响应 因为cpu的时间是宝贵的 所以会在响应后 交给软中断来处理 这样才能实现较高的利用效率
处理
当接收到中断信号后 就会根据中断信号 去找中断描述符表(IDT 通过idtr寄存器找到IDT地址)中寻找段选择子和段内偏移 通过段选择子去全局描述符(GDT)中寻找基地址 然后加上偏移地址获取真正的地址 如果开了分页机制 那么再根据这个地址进行分页转化 也就是线性地址转向真实的物理地址(比如二级分页机制的话 前10位获取页目录项从而定位到页目录再通过中12位获取页目录中第几项获取其基础地址然后加上最后10位偏移地址获取真实的地址)
GO底层
网站是看的这个:Introduction · 深入解析Go (gitbooks.io)
书籍是
Go语言设计与实现
面试技巧
协程,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态中执行)。
线程在切换的时候不会改变页表等,只需要进行寄存器的替换,但是进程在切换的时候需要把大量的内容给替换
切片是引用类型 而数组是值类型 []int这样定义是切片 [4]int这样定义是数组 然后数组传递过去不会导致原本的值改变 切片会导致
结构体中指针函数和普通函数
比如我定义一个结构体
type A struct {
}
func (a *A)Func1(){}
func (a A)Func2(){}
- 这里的a 其实由于golang都是值传递 所以在 func1 中a *则是a的指针被传递过去 然后对a进行操作的话 会修改变量的值 但是如果func2中对a进行操作就是对a的备份进行操作无法修改原本的值
字典实现
- 是通过hash链表 大概就是首先通过链表把各个桶链接起来 然后对key进行取hash然后取余 得到下标如果下标一致 则直接在桶后面添加这个value
接口实现
- 结构体中存储类型的hash值 并且存储一个unsafe指针 这样就可以实现各个类型的断言转化了
数组实现
- 数组主要是结构体中存储了长度 然后存储数组指针
切片实现
- 结构体中存储了长度和容量以及指针这样就可以实现动态扩容了
函数调用规范
先压入返回地址 然后压入参数最后压入返回参数 所以go的函数调用参数和返回值都是依赖于栈进行传递的
并且golang中的参数传递都是值传递 也就是拷贝一份
深/浅copy
深copy是复制对象的值 创建一个新的对象进行存储 所以修改新对象 不会影响原对象的值 内存地址不同
浅copy是复制对象的指针 这样新对象修改的时候老对象也会发生变化 比如Slice Map
package main
import "fmt"
func main() {
slices1 := []int{
1, 2, 3, 4,
}
slices3 := []int{
1, 2, 3, 4,
}
slices4 := slices3[1:]
slices4[1] = 6
slice2 := slices1
slice2[1] = 6
fmt.Println(slices1)
fmt.Println(slices1)
// [1 6 3 4]
//[1 6 3 4]
}
闭包
在go语言中闭包函数 所引用的父类变量都不能在栈上分配 因为这样父函数执行完毕后栈上变量就失效了 所以这些变量都是在堆上分配的 会专门产生一个闭包结构体来存储这些外部引用变量
一等公民
高阶函数编程:探索Go语言中的函数一等公民-腾讯云开发者社区-腾讯云 (tencent.com)
在给定的编程语言设计中,一等公民是指支持所有通常可用于其他实体的操作的实体。这些操作通常包括作为参数传递、从函数返回和赋值给变量。
- 参数传递
- 函数返回值
- 赋值给变量
Python
asyncio(TODO)
- await的for循环可能导致的runtimeError问题
Pwn
ret2dl
- 流程是 先执行跳转到GOT[3] 然后GOT[3]存储的是plt[1] 也就是先压reloc_arg参数 然后jmp到plt[0] plt[0]存储的是push link_map(GOT[1]) 然后跳转到_dl_runtime_resolve函数也就是GOT[2]
- 然后分析一下两个参数 一个是reloc_arg 我们可以通过这个知道我们要绑定的函数名字 也就是从reloc_arg为下标 然后rel_plt[reloc_arg]获取elf_rel信息 提取elf_rel.r_info信息 这个是个指针 然后解引 就获取了名字的下标 然后通过dynstr[st_nameh]获取函数的名字
- 那么我们如果可以伪造reloc_arg 然后让rel_plt表索引到bss段 我们可控区域 这样就可以伪造elf_rel的信息 从而伪造r_info的信息 让这个指针指向我们想要调用的函数 然后dynstr就可以直接调用我们的函数了
c - main函数参数含义
- 第一个参数argc 也就是传给程序的参数个数 包含了程序文件自己本身的名字 比如./new.exe a b 那么参数就是三个
- argv 字符串数组指针 包含程序名称
- envp 环境变量字符串数组的指针
canary 多线程绕过
参考文章:(´∇`) 欢迎回来! (cnblogs.com)
在创建新线程的时候 在为栈分配内存后,glibc在内存的高地址初始化TLS,在x86-64架构上,栈向下增长,将TLS放在栈顶部。 从TLS中减去一个特定的常量值,我们得到被新线程的stack register所使用的值。从TLS到pthread_create的函数参数传递栈帧的距离小于一页。 现在攻击者将不需要得到leak canary的值,而是直接栈溢出足够多的数据来复写TLS中的tcbhead_t.stack_guard的值,从而bypass canary。简单来说就是因此会顺便创建一个TLS,而且这个TLS会存储Canary的值,而TLS会保存在stack高地址的地方
格式化字符串
%*25$d从栈中取变量作为N,比如:栈25$处的值是0x100,那么这个格式化字符串就相当于%256d。(sample:pwn4-MidnightsunCTF-2020)
ORW沙箱绕过总结
[Pwn - Shellcode Summary | HeyGap's_Blog](https://heygap.github.io/2024/02/08/Pwn - Shellcode Summary/#1-1-shellcode-板子)
[沙箱绕过 | Brvc3's Base](https://brvc3.github.io/2021/05/03/沙箱绕过/#:~:text=绕过方式 禁用了execve或者system 通过 open read write 来读取flag example:,lgd 禁用了 open,write,read openat,所以直接 调用openat,然后除了 read,write,其实还有两个readv,和writev,这些就能绕过限制读取flag%2C有些连openat都禁用的可以 ptrace 修改syscall)
Seccomp BPF
linux2.6.23内核用ptctl来代替/proc/PID/seccomp进行添加禁用 2012后linux 3.5 增加了新的模式 过滤模式 我们可以允许系统调用2014年,Linux 3.17 引入了
seccomp()系统调用,seccomp()在prctl()的基础上提供了现有功能的超集
BPF就是在内核层起了一层虚拟机 这个虚拟机 起到了过滤作用 这样每次系统调用就会经过该过滤器 此过程不可逆
然后prctl中第二个参数代表操作的对象 如果这个参数为1 则对所有的用户都起作用 会让子进程都受到这个过滤器的限制
- ptctl还可以让内核进入严格模式 进程可用的系统调用就只有4个 read(), write(), _exit(), 和 sigreturn()
docker也运用了这项技术 实现了沙盒禁止
常规绕过
在禁用了大量函数的情况下 我们可以选择一些思路来进行绕过
- 切换为32位 错开禁用号 进行调用 修改cs寄存器的值 我们一般采用refq 0x23就是32位运行模式 0x33就是64位运行模式
fork一个新的线程 pipe + fork + exec: 创建一个管道
侧信道攻击(无write)
socket通讯 套接字函数来实现 当然前提是别是禁用所有用户
字节不够情况下
- 观察堆栈 用pop push等栈传递 因为字节很小 一些长的寄存器可以改为短的寄存器
io_uring利用
io_uring主要是两个环形缓冲区构成 sq 和cq 也就是submit queue 和completion queue 都是处于内核空间的 但是用户可以直接访问内核
- sq也就是存放用户提交的io请求
- cq也就是处理完的sq中的io请求就会填充到cq中 并且通知用户空间i请求完成
流程
io_uring_setup()系统调用创建io_uring实例- 提交请求:也就是将io写入sq
- io_uring_enter() 提交io事件并且等待其完成 int io_uring_enter(int fd, unsigned to_submit, unsigned min_complete, unsigned flags, sigset_t *sig); fd也就是
io_uring_setup的返回值 to_submit也就是要提交的事件数量 min_complete也就是函数返回之前要完成的事件最小数量 sig也就是信号集的指针 用于io完成的时候接受信号 返回值是完成的事件数量 - **io_uring_register()**用于注册内核用户共享缓冲区,如文件描述符、缓冲区等。 成功返回0
- **io_uring_unregister()**用于取消之前通过
io_uring_register()注册的资源。 - 首先使用
io_uring_prep_*()函数准备 I/O 操作,然后使用io_uring_submit()提交这些操作到io_uring中进行处理。io_uring_prep_readv():准备读取操作。io_uring_prep_writev():准备写入操作。io_uring_prep_poll_add():注册一个轮询事件。
- io_uring_enter() 提交io事件并且等待其完成 int io_uring_enter(int fd, unsigned to_submit, unsigned min_complete, unsigned flags, sigset_t *sig); fd也就是
- 内核处理 内核会定期检查sq如果有新的请求就
并行处理 也就是同时干 - 完成通知 当将内容填充进入cq 然后通知用户
- 用户顶级检查cq发现请求完成后 从cq中取出结果进行后续处理
优点
- 异步性
- 非堵塞性
- 批量处理
- 灵活性
refq和retf详解
retn (return near) 用栈中数据修改ip寄存器
retf (return far)用栈中数据修改cs:ip寄存器
retfq 和retf一样但是retfq是从64位转化到32位 retf是从32位转到64位
- 先弹出栈顶给ip然后弹出给cs寄存器 0x33(64位) 0x22(32位)
为什么用rax间接传参
比如我们没办法直接将一个较大的立即数通过push等直接推入栈 我们需要先赋值给rax 然后推入rax
arm架构函数调用规范 armv7和armv8的区别
[原创] CTF 中 ARM & AArch64 架构下的 Pwn-Pwn-看雪-安全社区|安全招聘|kanxue.com
[ARM pwn 环境搭建+基础入门 | Pwn进你的心 (ywhkkx.github.io)](https://ywhkkx.github.io/2022/08/29/ARM pwn 环境搭建+基础入门/)
- armv7主要是32位指令集 armv8是64位指令集合
armv7
32位 是利用的r寄存器 一共16个 然后R0-3一啊不能用作函数的参数传递和返回值使用 也可以在程序中保存立即数
- r7存储系统调用号
- r12 也就是ip r11作为栈指针用作栈底可用于栈回溯 r13sp栈指针 r14 lr链接寄存器 r15 pc 程序计数器
- r0存储float返回值 r0-r1存储double
- 前四个参数都是r0-r3寄存器传递 然后后面通过栈传递
- 在进行bl等指令的时候 pc存入lr 然后更新pc 就可以通过lr寄存器进行恢复
- 返回值会被优化 也就是当返回值是一个结构体的时候那么r0就不是第一个参数而是返回值的指针
- 返回是通过pop {pc}进行的返回
函数调用规范
- 也就是先保存栈底和下一个指令地址
- 然后r11设置为栈顶 然后sp展开 这里和x86不同的是arm架构是先进行栈帧展开 再进行的函数跳转
push {r11, lr} /* 序幕的开始,将帧指针和LR保存到堆栈 */ add r11, sp, #0 /* 设置栈底帧 */ sub sp, sp, #16 /* 序幕结束,在堆栈上分配一些缓冲区(这也为堆栈帧分配空间) */- 然后就是寄存器赋值
mov r0, #1 /* 设置局部变量 (a=1)。 这也用作设置函数 max */ 的第一个参数 mov r1, #2 /* 设置局部变量 (b=2)。 这也用作设置函数 max */ 的第二个参数 bl max /* 调用/分支到函数 max */- 返回的时候 也就是将sp变回栈底 然后将栈底和pc返回原本的值
sub sp, r11, #0 /* 结尾的开始,重新调整堆栈指针 */ pop {r11, pc}arm中ldr是load register str也就是store register
- load register 也就是将指针的值存入寄存器中
- store register 也就是将寄存器的值存入指针中
arm中str r2 ,[r1 ,#2]也就是存入r+2的位置 但是r1的值不改变
- str r2,[r1,#2]!也就是r1的值会发生改变 也就是将最后的地址写入原寄存器中 所以就是+4 !的意思是请求回写
- ldr r2,[r1],#-2 也就是r1直接赋值给r2 然后r1减去2
armv8
arm64架构大差不差 也就是把lr和栈底压入栈 然后栈减去
寄存器名字叫做X了 X0-x7用作参数传递 X0用作函数返回值 x8用作调用号 x32是pc寄存器 x30也就是函数返回值 然后函数调用的时候直接将原本的sp压栈 然后sp减去一定值 最后再回来
BR指令 BLR指令
mips架构的函数调用规范
mips是存在叶子函数的 叶子函数也就是函数中不会去调用其他任何函数 非叶子函数就是还会调用其他的函数
- a调用b的情况 非叶子函数 会将返回地址存入栈中
- 叶子函数的话 则返回a的i地址存储再ra寄存器中
- 当函数返回的时候 如果是非叶子函数 则从堆栈中取出返回地址 然后存入ra寄存器 然后再跳转返回
- 叶子函数则直接ra进行跳转
- 返回值存储再v0-v1中
[mips pwn | p1Kk's World!](https://p1kk.github.io/2020/01/01/异构pwn/mips pwn/#缓冲区溢出分析示例)
- 调用者把参数都保存在a0-a3寄存器 也就是前4个用寄存器保存后面用栈保存
- 返回地址存储再ra寄存器上
phpPwn堆管理机制
[第5章 内存管理 - 5.1 Zend内存池 - 《试读] PHP7内核剖析》 - 书栈网 · BookStack
php中针对内存的操作进行了一层封装 用于替换内存操作 实现malloc free等操作 也就是参考了tcmalloc函数
php内存管理中有三种颗粒度的内存块 也就是chunk page slot 每个chunk占2m 然后page占比4kb 一个chunk会被分配为page 然后page再分配为slot
也就是申请大于2m则申请chunk 大于3/4page就申请page 然后小于3/4page 就申请slot
- Huge(chunk): 申请内存大于2M,直接调用系统分配,分配若干个chunk
- Large(page): 申请内存大于3092B(3/4 page_size),小于2044KB(511 page_size),分配若干个page
- Small(slot): 申请内存小于等于3092B(3/4 page_size),内存池提前定义好了30种同等大小的内存(8,16,24,32,…3072),他们分配在不同的page上(不同大小的内存可能会分配在多个连续的page),申请内存时直接在对应page上查找可用位置
都是受到heap结构体管理 用于管理上面三种内存的分配 main_chunk属性是chunk链表 free_slot就是一些固定大小的slot链表 类似于lagrebin的管理模式 2024d3中phppwn那题就是通过劫持slot链表来进行任意写
- 这里利用的是mmap函数进行的申请内存 而非malloc函数的brk等
cpp堆管理机制(todo)
musl堆管理器
轻量级的嵌入式开发glibc库
堆利用
因为太过重要 以及知识点体系过于庞大 所以单独拿出来 house系列主要是这个Glibc堆利用之house of系列总结 - roderick - record and learn! (roderickchan.github.io)文章进行总结得很好 这里大量直接进行copy
- 有一些很容易想要的一些利用方式这里就不单独列出来了 比如修改fd 控制malloc到的数据 主要是总结一些利用难度较高 比较成体系的利用方式
malloc函数中的一些检查机制
这个主要是写在源码注释中了 翻阅源码即可然后找到一个很好用的网站写了源码中的宏定义heap - 5 - malloc、free函数相关的宏定义 | Kiprey's Blog
常见利用技巧
overlapping: 这个技巧主要是通过off_by_null漏洞进行控制size位的prev_inused这个位 这个操作十分方便 我可以间接利用然后实现劫持正在使用的合法chunk 然后我们就可以绕过一些题目中的free检查 比如有一些题必须free 表中记录正在使用的chunk才是合法的 无法直接double free 我们可以通过劫持合法chunk轻松实现double free具体就是让我们要劫持的chunk刚好处于合并区间之间比如:malloc 五个chunkchunk1,chunk2,chunk3,chunk4,chunk5然后chunk1的内容部分构造好fakechunk根据版本的安全检查进行构造 如果版本较高我们需要计算并且构造好size区域fd以及bk然后chunk2就为我们要劫持的chunk 我们通过chunk3写入内容覆盖chunk4完成覆写p位并且构造好prev_size让它刚好指向我们的fakechunk然后最后我们free chunk4触发合并机制 让chunk4到fake chunk之间的内容全部进入unsortedbin中 这样我们malloc下来就可以进行劫持了 这个方法较为好用
House of force(top chunk 利用)
主要是我们能溢出数据到
topchunk的size区域 然后malloc的时候malloc一个超大值让它刚好到我们想要控制的地址附近去
- 范围:
2.23——2.29 - 因为2.29后加入了对size区域的检查 导致我们没办法再通过直接获取任意地址
largebin attack
主要是利用了unsoretdbin 的入链机制 也就是当我们所需要的chunk不属于fastbin tcachebin 已有chunk大小 需要从unsrotedbin中取chunk的时候 触发unsortedbin分类合并机制 如果unsortedbin中chunk有一个chunk属于largebin的范围 并且比largebin chunk的最小的chunk还小 我们如果可以劫持largebin 最小的那个chunk 就可以触发一个任意写已知地址 并且还可以实现堆地址的泄露 十分好用的技巧
smallbin attack(todo)
House of kiwi
利用
malloc_assert的fflush(stderr);来触发调用链
- 通过触发assert函数中的fflush 然后调用
_io_file_jumps的_io_FILE_SYNC指针 并且rdx恒为_IO_helper_jumps指针 - 我们可以将
_io_file_sync指针调整为setcontext+61触发rdx到寄存器的赋值 然后我们劫持_IO_helper_jumps(0xa0 0xa8)实现- 修改
IO_helper_jumps + 0xA0 and 0xA8分别为可迁移的存放有ROP的位置和ret指令的gadget位置,则可以进行栈迁移
- 修改
house of cat
可以打fsop 也就是打main函数返回 程序执行exit libc执行abort(高版本已经删除) __malloc_assert则是在malloc中触发,通常是修改top chunk的大小。
触发
__malloc_assert调用__fxprintf- 主要是想办法调用
_IO_xxx_jumps
__malloc_assert (const char *assertion, const char *file, unsigned int line, const char *function) { (void) __fxprintf (NULL, "%s%s%s:%u: %s%sAssertion `%s' failed.\n", __progname, __progname[0] ? ": " : "", file, line, function ? function : "", function ? ": " : "", assertion); fflush (stderr); abort (); }- 主要是想办法调用
然后__fxprintf又调用
__vfxprintf函数 然后调用locked_vfxprintf然后调用__vfwprintf_internal然后调用对应的vtable函数
image-20240602023528121
printf/puts io调用链(TODO)
linux Kernel
kernel部分比较重要需要重新梳理一下 以及理顺一些脉络
段保护模式/页保护模式
一般来说我们的逻辑地址会经历转化才回到真正的物理地址去
- 虚拟地址->线性地址->物理地址
- 32位我们比较熟悉 在复习中断的时候 我们已经大概的复习了一下两级分页机制 然后下面图是大佬博客里面的四级分页机制的图 讲解得很仔细
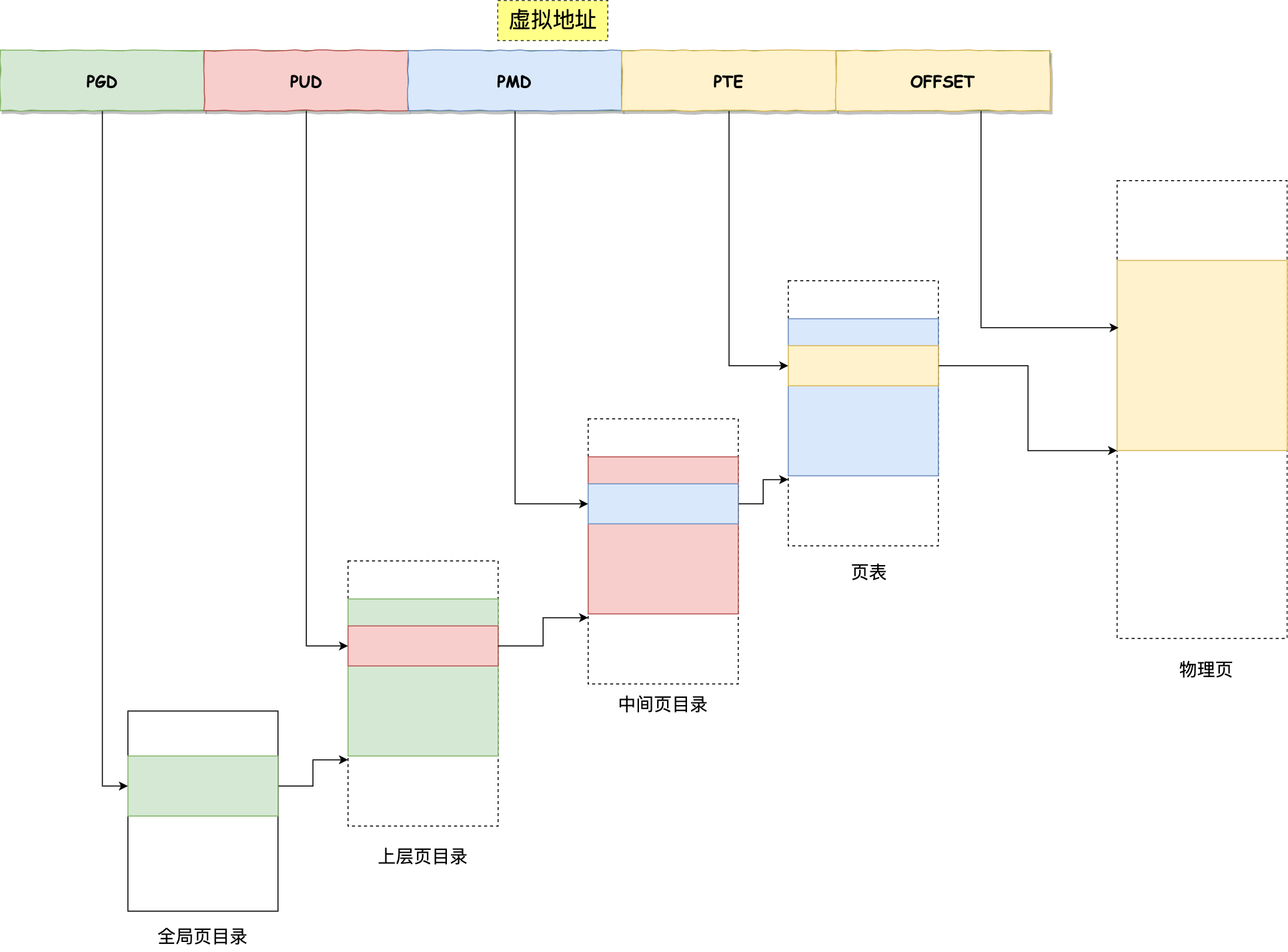
虚拟地址转化为线性地址
依赖于段选择子也就是段寄存器 段选择子再去
实/保护模式
实模式就是简单通过cs:ip这样的方式直接访问内存
保护模式就是通过段机制 来间接访问内存
进程
5.1 进程、线程基础知识 | 小林coding (xiaolincoding.com)
一般多线程 如果一个线程挂了就会导致全部线程崩溃 因为线程是共享内存的 如果一个线程崩溃了就会导致内存有错误 不确定会带来一些难以想象的后果 所以其他线程也会更随着崩溃
- 操作系统通过
pcb进程控制块来描述进程pcb通常是相同状态的链表链接在一起的 - 进程是资源(包括内存、打开的文件等)分配的单位,线程是 CPU 调度的单位;
execve
- 是先将程序头写入进入新的内存 然后通过cow进行copy其他代码部分
- 覆盖原有的进程 会改变代码段
oom机制
当进行申请内存 内存不够 并且回收一些内存(kswapd)后依旧不够就会杀死一个物理内存占用较高的进程 直到释放足够的内存位置
- 回收内存(lru算法):
- 内存页(大多数内存页都是可以直接释放的 以后有需要了 在进行重新读取即可 如果已经被程序修改过了 并且暂时没有写入磁盘的数据(脏页) 会先写入磁盘 然后再进行内存的释放)
- 匿名页:比如栈堆等 这些内存随时有可能再次被访问所以不能直接回收所以会利用
swap机制先写入磁盘中 然后再释放内存
如何保护一个进程不被 OOM 杀掉呢?
- oom主要是根据进程的得分来进行评估是否要杀掉
- 第一,进程已经使用的物理内存页面数。
- 第二,每个进程的 OOM 校准值 oom_score_adj。它是可以通过
/proc/[pid]/oom_score_adj来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
- 所以我们可以通过
oom_score_adj来避免被杀 比如把这个值设置位-1000
linux的内存管理
32位操作系统和64位操作系统在内核内存的分布是不一样的
首先在32位操作系统中内核虚拟内存和进程虚拟内存是无缝衔接的 而64位操作系统内核和用户空间是存在一大块空洞空间的
- 存在原因是因为64位用高16位作为标记 也就是0x0000 7fff ffff f000以下为用户 0xffff 8000 0000 0000以上是内核
32位是4g 64位是16 EB
32位内核内存分布
- 最先是896mb(直接映射区域)是和物理内存一一对应的 但是其还是使用的虚拟地址并且也要通过映射转化为物理地址
- 其中前16mb是DMA区域 用于存放
- 剩下就是NORMAL区域
- 高端内存也就是896mb之上的区域(128mb)采用的是动态映射技术
- vmalloc 区域 也就是使用vmalloc进行申请的区域
- 永久映射区 也就是允许建立与物理高端内存的长期映射关系 比如内核通过
alloc_pages函数申请物理内存页 这些物理内存页通过kmap映射到永久映射区 - 固定映射区
- 临时映射区 也就是缓冲区的作用比如做一些copy操作的时候
图片
- 最先是896mb(直接映射区域)是和物理内存一一对应的 但是其还是使用的虚拟地址并且也要通过映射转化为物理地址
64位内核内存分布
64位的由于空间巨大 不需要和32位一样精细规划 所以相对而言简单一些
- 64t的直接映射区
- 32t的vmalloc区域
- 1t虚拟内存映射区
- 512mb代码段
伙伴算法
- 分配内存页使用
alloc_pages来完成 而alloc_pages是通过rmqueue()来分配内存页
- 分配内存页使用
如果4g物理内存的机子上面申请8g内存会怎样
4.4 在 4GB 物理内存的机器上,申请 8G 内存会怎么样? | 小林coding (xiaolincoding.com)
- 如果32位操作系统的情况下 我们申请就会失败 因为32位操作系统虚拟内存也就4g
- 64位操作系统是成功的 因为cow的关系 我们只有真的写的时候才会影响实际的物理内存
Pwn linux kernel
调试
环境拿下来后可以通过指令直接运行起内核 然后通过调试
qemu-system-x86_64 -initrd rootfs.cpio -kernel bzImage -append 'console=ttyS0 root=/dev/ram oops=panic panic=1' -monitor /dev/null -m 128M --nographic -s
当题目中不存在vmlinux文件的时候 我们要调试内核或者查看rop链的时候 可以用 extract-vmlinux 命令可以从 bzImage种提取vmlinux
一般情况下我们需要提取出来ko文件 目前linux kernel文件系统 主要分为两种:
ext4和cpio两种我们的提取方式不同ext4直接将文件系统挂载在已有的目录中mkdir ./rootfssudo mount rootfs.img ./rootfs- 此时这个时候这个目录下就已经有了我们的文件目录
cpio这个稍微多一步也就是 解压文件系统 重打包mkdir extracted; cd extractedcpio -i --no-absolute-filenames -F ../rootfs.cpio- 此时与其它文件系统相同,找到
rcS文件,查看加载的驱动,拿出来 find . | cpio -o --format=newc > ../rootfs.cpio
常规保护机制
KPTI:Kernel PageTable Isolation,内核页表隔离KASLR:Kernel Address space layout randomization,内核地址空间布局随机化- 也就是
kernel的ASLR
- 也就是
SMEP:Supervisor Mode Execution Prevention,管理模式执行保护- 也就是内核状态下不允许执行用户态的代码
SMAP:Supervisor Mode Access Prevention,管理模式访问保护- 也就是内核状态下不允许访问用户态的数据
SMEP与SMAP这两个都是通过cr4寄存器来进行判断开启关闭的 所以我们如果可以修改cr4的值 我们就可以实现绕过这两个保护
Stack Protector:Stack Protector又名canary,stack cookiekptr_restrict:允许查看内核函数地址dmesg_restrict:允许查看printk函数输出,用dmesg命令来查看MMAP_MIN_ADDR:不允许申请NULL地址mmap(0,....)
常用利用结构体
- tss_struct 中cr3主要是存储页目录的物理地址 cs寄存器末尾存储当前的权限等级
mm_struct
主要负责对内存区域的大致划分结构体属性存储的就是各个内存区域的边界
vm_arena_struct结构体(双向链表)
描述一个内存区域的开始结束 权限 是否能共享(mmap)等信息 以及存储了虚表指针(open close 等)
cred结构体
创建一个新进程的时候 内核会申请一个
cred结构体 存放进程信息 主要是一些权限信息之类的
tty_struct
学习文章:tty_struct数据结构_ttystruct-CSDN博客
linux kernel pwn学习之伪造tty_struct执行任意函数_tty struct-CSDN博客
tty_driver 是驱动通过alloc_tty_driver函数分配的 也就是调用kzalloc tty0也就是控制台的文件体现
tty_driver的flags等在未被赋值的时候所有值都是0
当open(ptmx)的时候会初始化
tty_struct攻击手段就是利用在调用对
ptmx驱动进行write操作的时候我们是利用的tty_struct结构体中虚表进行的操作 所以我们如果可以伪造这个vtable然后指向我们的可控区域 来实现函数的调用
堆喷/脏管道学习(TODO)
msg_msg消息队列(TODO)
kmalloc和vmalloc区别(TODO)
缺页内核和用户态(userfaultfd)(TODO)
如果要提升条件竞争的概率,可以采用userfaultfd
sk_buff(TODO)
dirty cow/pipe(TODO)
smep和smap的绕过(TODO)
V8/jsc(TODO)
标记指针
- v8中利用指针标记技术在v8的堆指针中存储额外的数据 比如32位操作系统下最低有效位用来区分smis/堆指针 第二个最低有效位来区分强引用和弱引用 64位操作系统用前32位进行当作负载
- 强引用也即是垃圾回收器不会去回收这个对象 内存不足也不会去回收 必须是显式释放
- 软引用用于描述一些有用但不是必须的对象 内存不足有可能被回收比如java中用new SoftReference来进行引用
- 弱引用 下次垃圾回收就有可能被回收
压缩指针
- v8 将高32位存储在r13寄存器中
js对象基础属性
- prototype 也就是js对象都是继承自另外个对象 也就是父对象 父对象被称之为原型对象(null除外 它没有自己的原型对象)
- 所以当调用对象的函数或者属性的时候 如果没有该属性或者方法就会去原型对象上面查找 如果找到不到就一直向上寻找直到最顶层的Object.prototype 如果最自己本身具备就不会去找原型
编译整体流程(TODO)
如何调试(TODO)
编译原理
- 编译器主要是四个阶段
- 预处理
- 比如对宏进行展开
- 编译
- 生成汇编语言
- 语法分析(syntax analyzing)
- 语义分析()
- 生成中间代码
- 代码生成
- 生成汇编语言
- 汇编
- 链接
- 预处理
语法解析(TODO)
TOken生成(TODO)
- ebnf语法
AST生成(TODO)
字面量语法树
一元运算抽象语法树
二元运算抽象语法树
中间代码生成(TODO)
链接与库(TODO)
ld的链接(TODO)
开发框架(TODO)
消息队列
kafka
- senfile
- 零copy技术
RabbitMQ
RocketMQ
postgreSQL(数据库)
- 其中的notify推送机制